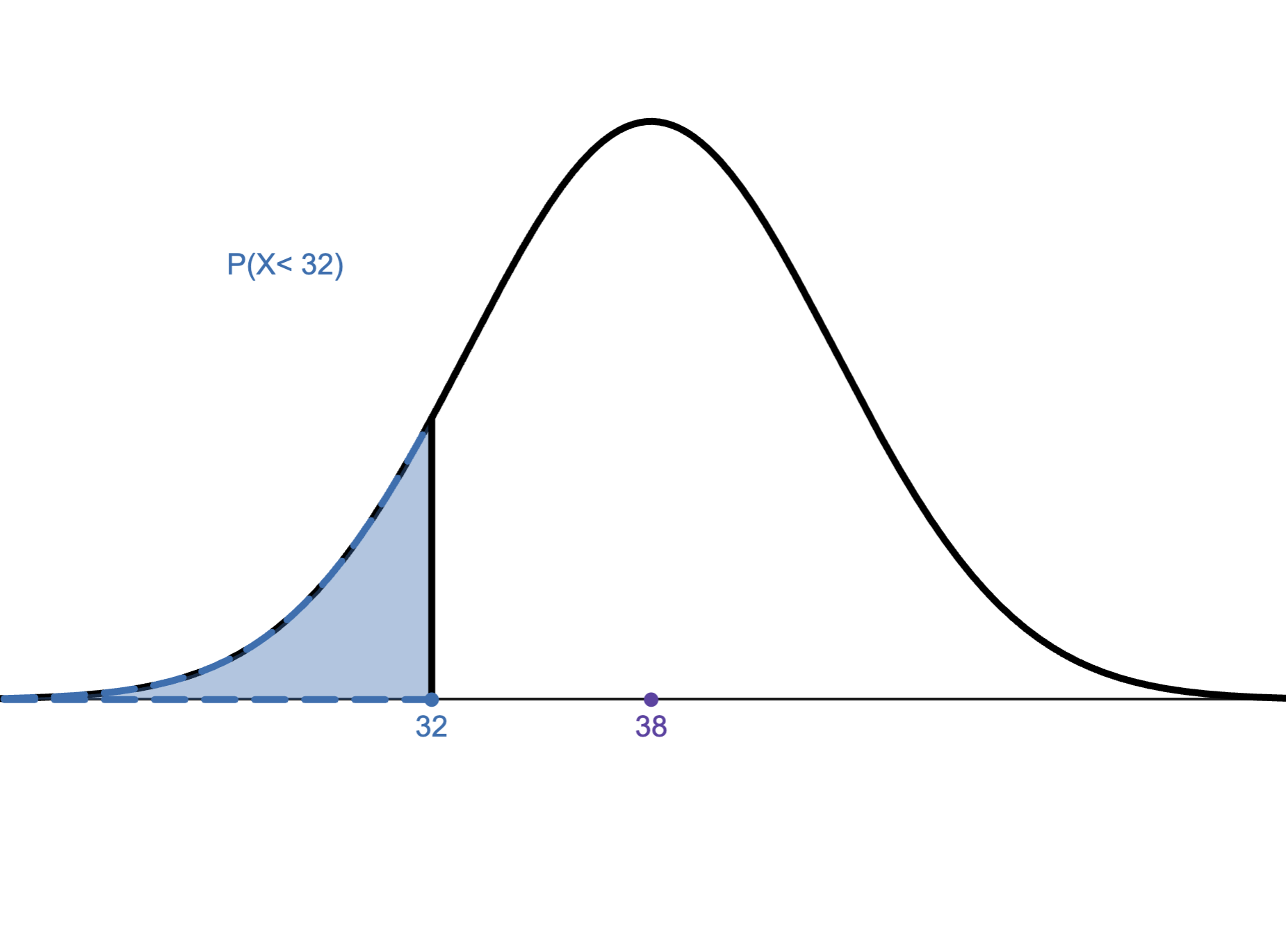
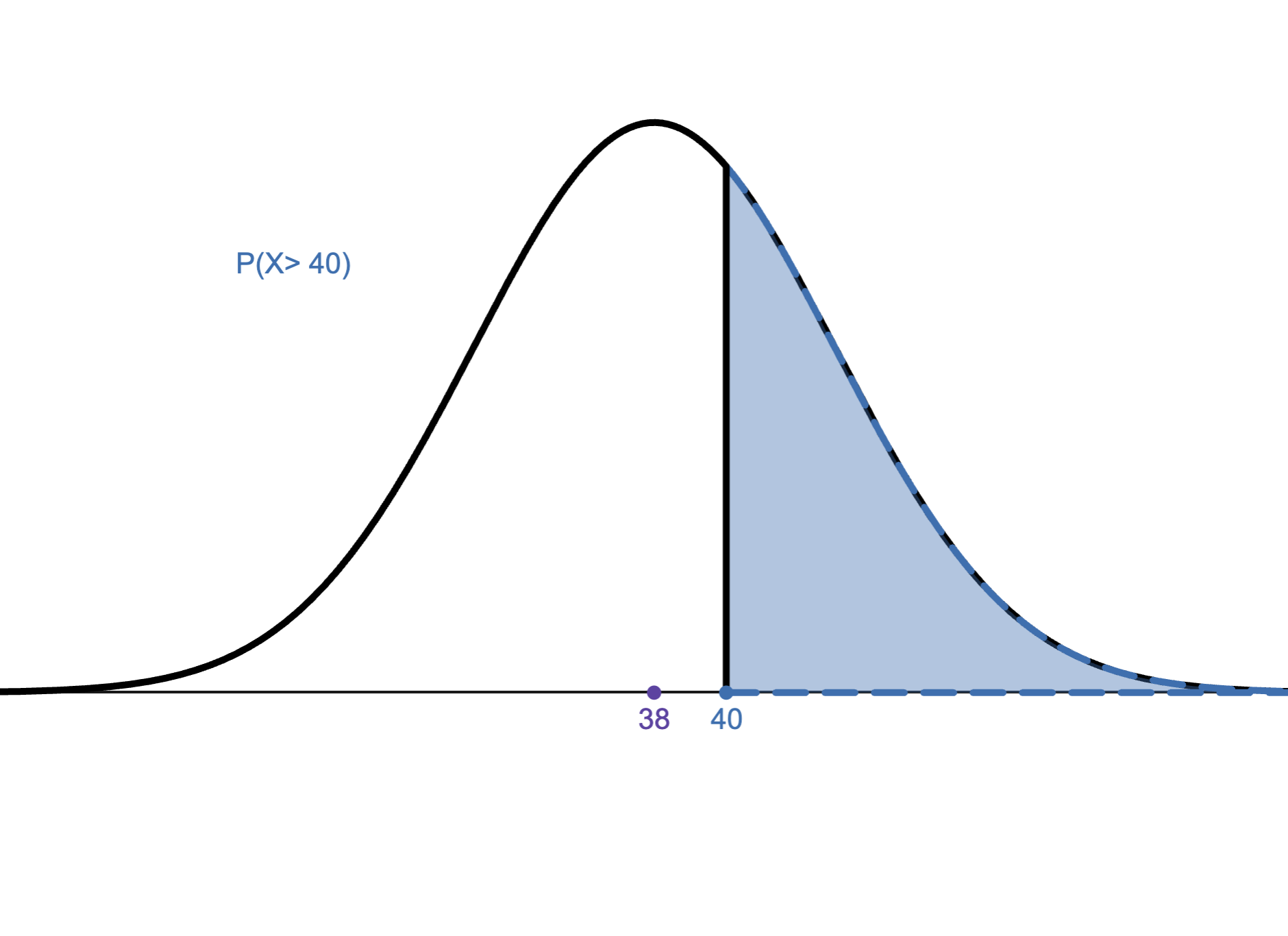
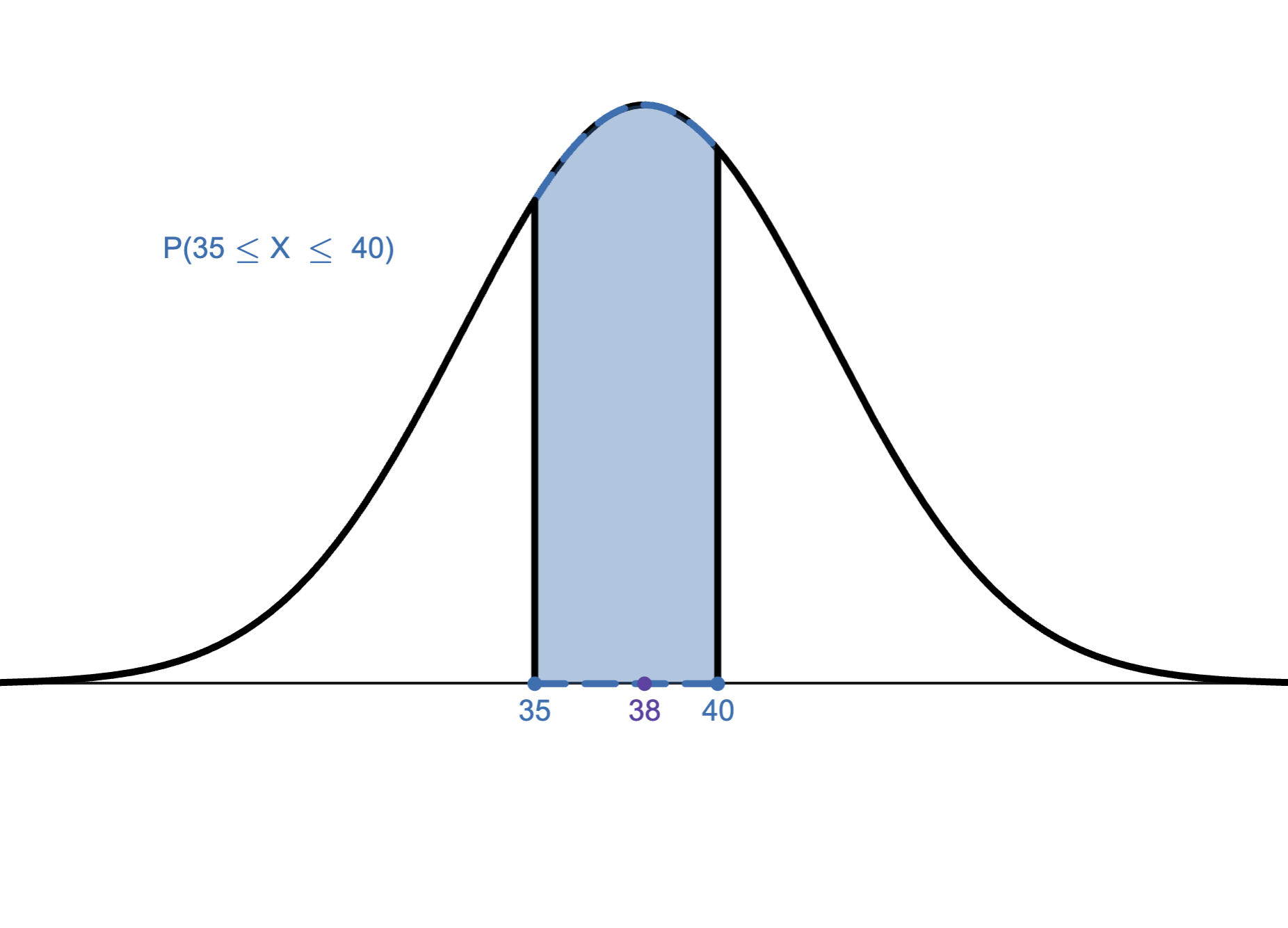
1.
Quiz outcome \(\boxed{1b}\text{:}\)
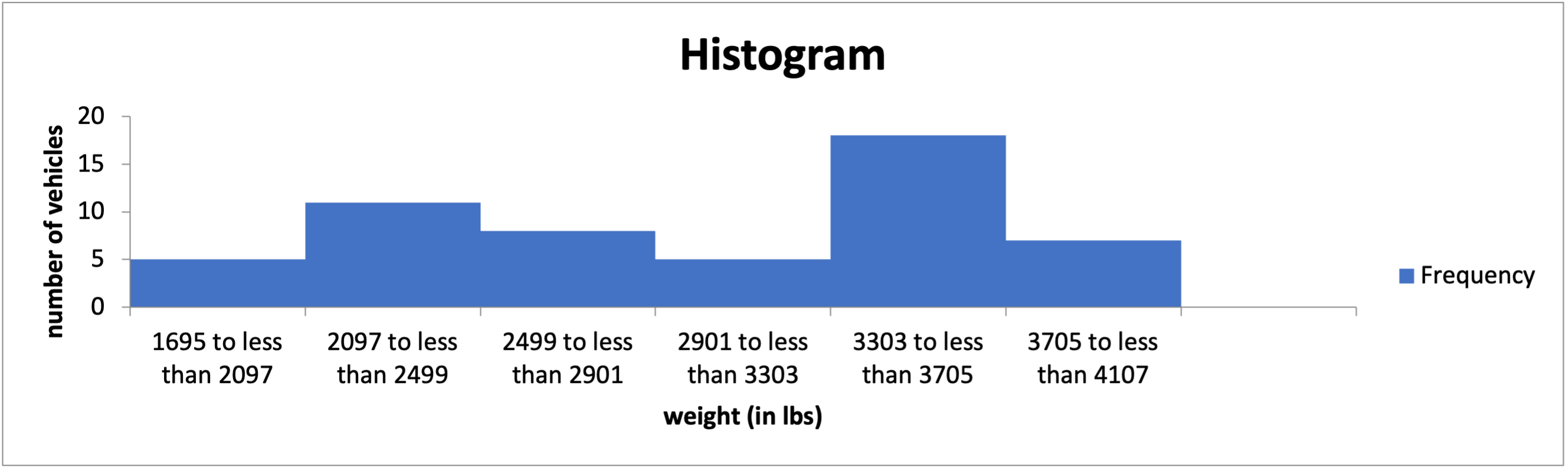
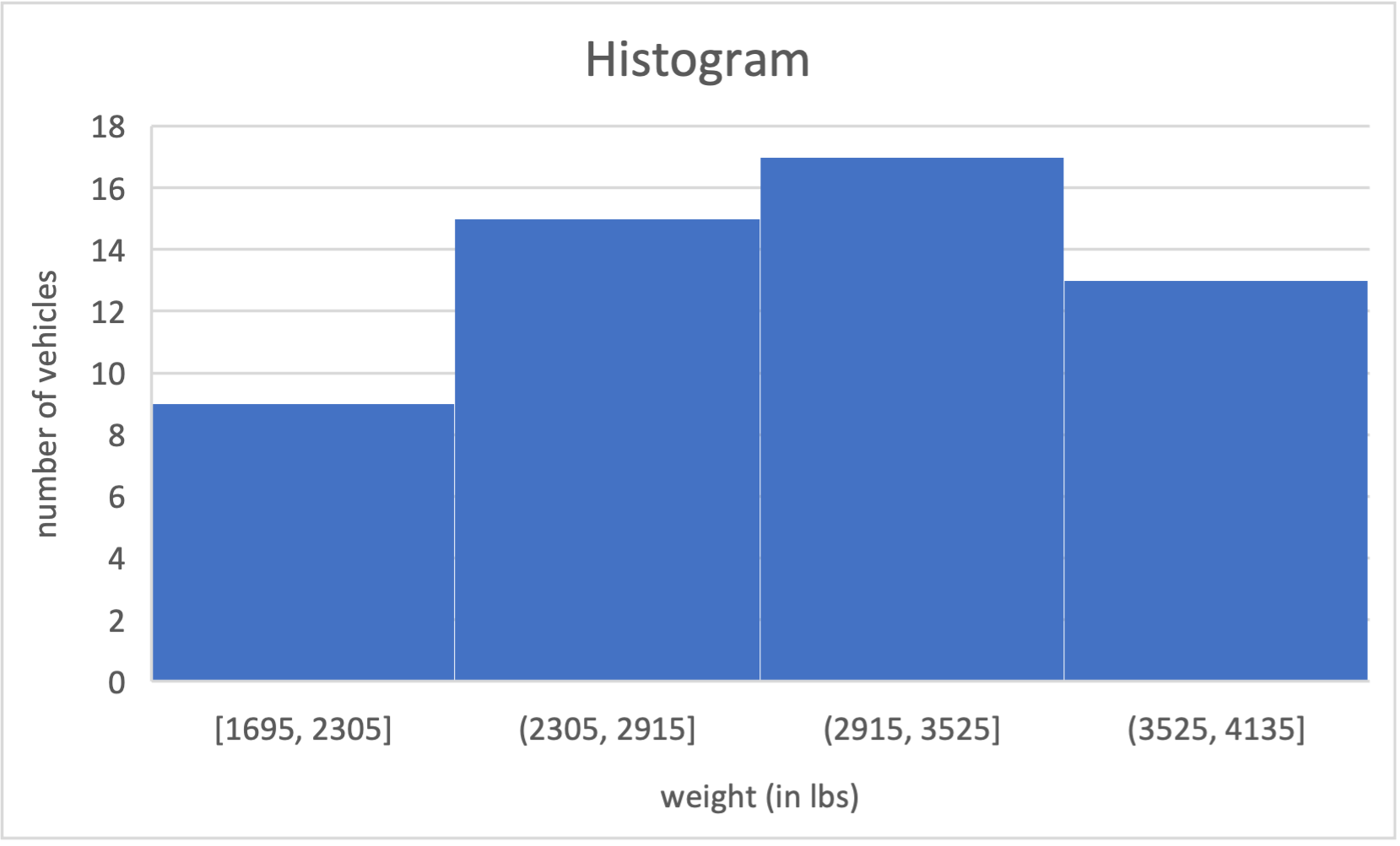
We want to create a histogram using the Data Analysis add-in in Excel. If we use the \(2^k\geq n\) Rule to find the number of bins, which of the following would be a histogram for “weight (in lbs)” in the Excel file below?